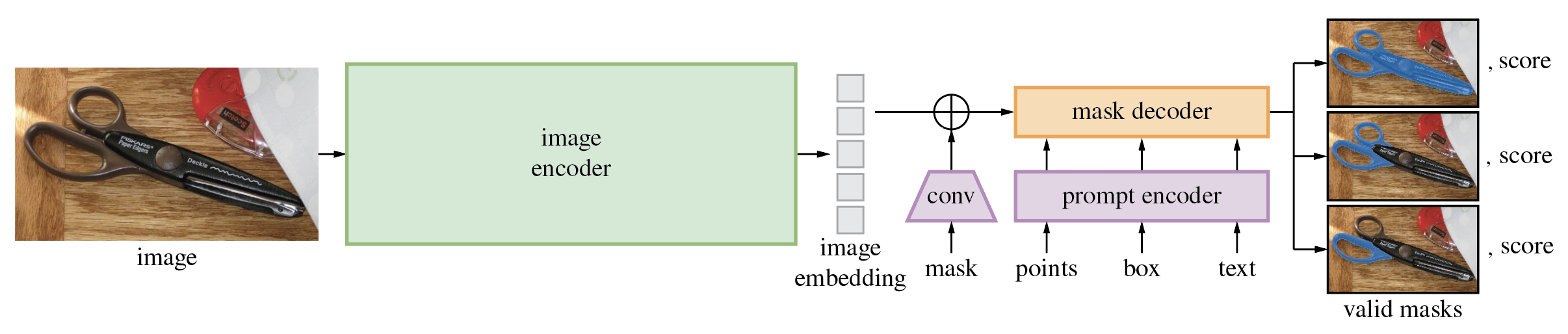
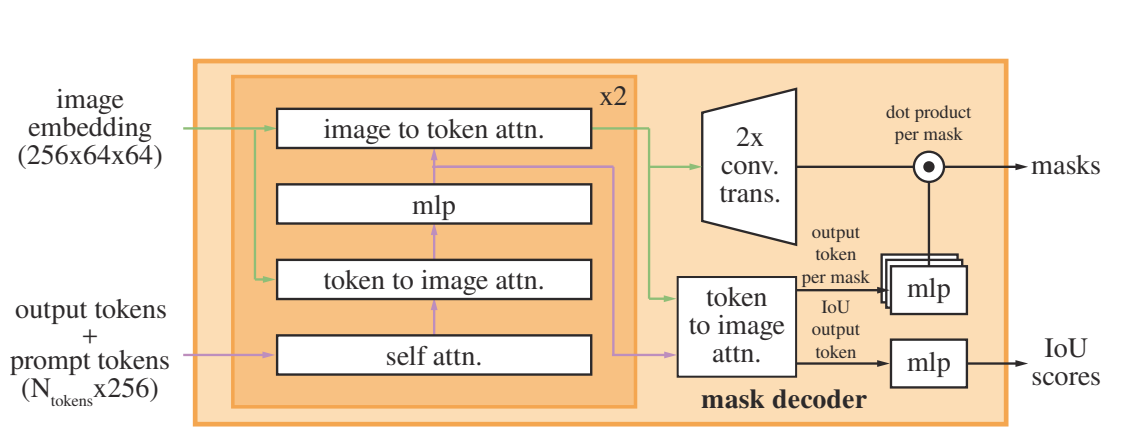
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
| class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
"""
Encodes prompts for input to SAM's mask decoder.
Arguments:
embed_dim (int): The prompts' embedding dimension
image_embedding_size (tuple(int, int)): The spatial size of the
image embedding, as (H, W).
input_image_size (int): The padded size of the image as input
to the image encoder, as (H, W).
mask_in_chans (int): The number of hidden channels used for
encoding input masks.
activation (nn.Module): The activation to use when encoding
input masks.
"""
super().__init__()
self.embed_dim = embed_dim
self.input_image_size = input_image_size
self.image_embedding_size = image_embedding_size
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
self.num_point_embeddings: int = 4
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
self.point_embeddings = nn.ModuleList(point_embeddings)
self.not_a_point_embed = nn.Embedding(1, embed_dim)
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
self.no_mask_embed = nn.Embedding(1, embed_dim)
def get_dense_pe(self) -> torch.Tensor:
"""
Returns the positional encoding used to encode point prompts,
applied to a dense set of points the shape of the image encoding.
Returns:
torch.Tensor: Positional encoding with shape
1x(embed_dim)x(embedding_h)x(embedding_w)
"""
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
"""Embeds point prompts."""
points = points + 0.5
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""Embeds mask inputs."""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
def _get_batch_size(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> int:
"""
Gets the batch size of the output given the batch size of the input prompts.
"""
if points is not None:
return points[0].shape[0]
elif boxes is not None:
return boxes.shape[0]
elif masks is not None:
return masks.shape[0]
else:
return 1
def _get_device(self) -> torch.device:
return self.point_embeddings[0].weight.device
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Embeds different types of prompts, returning both sparse and dense
embeddings.
Arguments:
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
and labels to embed.
boxes (torch.Tensor or none): boxes to embed
masks (torch.Tensor or none): masks to embed
Returns:
torch.Tensor: sparse embeddings for the points and boxes, with shape
BxNx(embed_dim), where N is determined by the number of input points
and boxes.
torch.Tensor: dense embeddings for the masks, in the shape
Bx(embed_dim)x(embed_H)x(embed_W)
"""
bs = self._get_batch_size(points, boxes, masks)
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
if points is not None:
coords, labels = points
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
if masks is not None:
dense_embeddings = self._embed_masks(masks)
else:
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
)
return sparse_embeddings, dense_embeddings
|